

webスクレイピングとやらをやってみたくて、Udemyの講座を受講した。
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)
基礎から丁寧に解説してくれており、実際に手を動かしながらやってみる形式で、演習問題もあり、非常に良質の講座でした。
しかし、いかんせん脳みそが小さいものだから、習った内容が盛りだくさん(普通の人にとっては盛りだくさんではないのかもしれない)で、ごっちゃごちゃに混乱状態になってしまった。
で、整理するための備忘録その4です。
ちなみにpython,webスクレイピングとも超初心者です。
前回まではBeautifulSoupで要素内のテキストやURLを取得するときのメソッド、select,find,find_allについて、をやりました。
今回はSeleniumの要素をつかむときのメソッド。seleniumではfind_elementというのを使うらしい。
そもそもseleniumnを使うにはseleniumやwebdriver(?)とやらをインストールしたりすることが必要だったりするのですが、講義の中で手引きとともにやったのですが、忘れてしまったためその部分は割愛します。別のサイトを見てください。。。
1.find_elementの種類
find_element は一つの要素を、
find_elements は複数の要素を取得、リストで返します。
| 種類 | 説明 |
|---|---|
| find_element_by_id(“id”) | id属性で要素を検索 |
| find_element_by_name(“name”) | name属性で要素を検索 |
| find_element_by_class_name(“class属性”) | class属性で要素を検索 |
| find_element_by_tag_name(“タグ名”) | タグ名で要素を検索 |
| find_element_by_xpath(xpath) | xPathで要素を検索 |
| find_element_by_css_selector(cssセレクタ) | cssセレクタで要素を検索 |
| find_element_by_link_text(リンクテキスト) | リンクテキストで要素を検索。文字列に一致するリンクを取れる。 |
| find_element_by_partial_link_text(リンクテキスト) | リンクテキストの部分一致で要素を検索。文字列を含むリンクを取れる。 |
2022.8月現在。上記の書き方は非推奨になっているとのことで、この書き方をすると、要素の検索はできるものの怒られメッセージが出ます。怒られるので、たぶん以下の書き方が推奨なのかしら。
今の書き方は
| 種類 | 説明 |
|---|---|
| find_element(By.ID,”id”) | id属性で要素を検索 |
| find_element(By.NAME,”name”) | name属性で要素を検索 |
| find_element(By.CLASS_NAME,”class属性”) | class属性で要素を検索 |
| find_element(By.TAG_NAME,”タグ名”) | タグ名で要素を検索 |
| find_element(By.XPATH,”xpath”) | xPathで要素を検索 |
| find_element(By.CSS_SELECTOR,”cssセレクタ”) | cssセレクタで要素を検索 |
| find_element(By.LINK_TEXT,”xxx”) | リンクテキストで要素を検索。文字列に一致するリンクを取れる。 |
| find_element(By.PARTIAL_LINK_TEXT,”xxx”) | リンクテキストの部分一致で要素を検索。文字列を含むリンクを取れる。 |
この書き方をする際はByをインポートする必要があるらしい。(たぶん)
from selenium.webdriver.common.by import By
2.seleniumでいろいろやってみる
やってみる。テスト用のページでやっています。
テスト用
(1)最初の書き出し
まず最初にいろいろインポートする。
ちなみにブラウザはGoogleChromeを利用。コードを書くのはAnacondaのjupyterNotesbookを使用しています。jupyterNotesbookで一つ一つ実行して確かめながらやっています。
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome("ここはchromedriverの場所")sleepは何秒待って、としてくれるやつ。
webdriverはseleniumを使うときの基本的なやつ。
from selenium.webdriver.common.keys import Keys
は文字入力したり、キー操作するときに使うライブラリらしい。
下表は以下サイトより引用させていただきました
https://snova301.hatenablog.com/entry/2018/11/22/194109
| アクション名 | コマンド |
|---|---|
ALTキー(通常キーと組み合わせ、例はalt + f) | element.send_keys(Keys.ALT, 'f') |
Ctrlキー(通常キーと組み合わせ、例はctrl + a) | element.send_keys(Keys.CONTROL,'a') |
シフトキー(通常キーと組み合わせ、例はshift + abc) | element.send_keys(Keys.SHIFT,'abc')) |
| COMMANDキー(mac) | element.send_keys(Keys.COMMAND) |
| スペースキー | element.send_keys(Keys.SPACE) |
| Enterキー | element.send_keys(Keys.ENTER) |
| リターンキー | element.send_keys(Keys.RETURN) |
| タブキー | element.send_keys(Keys.TAB) |
| Deleteキー | element.send_keys(Keys.DELETE) |
| HOMEキー | element.send_keys(Keys.HOME) |
| ENDキー | element.send_keys(Keys.END) |
| ESCAPEキー | element.send_keys(Keys.ESCAPE) |
| イコール(=)入力 | element.send_keys(Keys.EQUALS) |
| F1キー | element.send_keys(Keys.F1) |
| ←キー | element.send_keys(Keys.LEFT) |
| ↑キー | element.send_keys(Keys.UP) |
| ページダウンキー | element.send_keys(Keys.PAGE_DOWN) |
| ページアップキー | element.send_keys(Keys.PAGE_UP) |
from selenium.webdriver.common.by import By
は、find_element(By.〇〇)を使うときに必要、なのだと思う。違ったらごめんなさい。ご指摘ください。
driver = webdriver.Chrome(“ここはchromedriverの場所”)
これで、クロームが操作できるようになるみたい。
webdriver.Chromeの引数にはchromedriverを保存した場所を指定する。
たぶんほかの方法もあると思います。。。
url = "https://mwkexcelfriend.com/testtest/"
driver.get(url)
sleep(3)テスト用の固定ページを開きます。https://mwkexcelfriend.com/testtest/
変数urlにテスト用ページのURLを代入します。
driver.get(url) でページを開きます。
sleep(3) で3秒待ちます。
(2)開発者用ツール(デベロッパーツール)でサイトの中身を見る方法
開いたページで、右クリック→検証でGoogleの開発者用ツールを開き、ここをクリックしたいんだけどなんてタグかな?idはあるかな?など調べながらスクレイピングを行います。
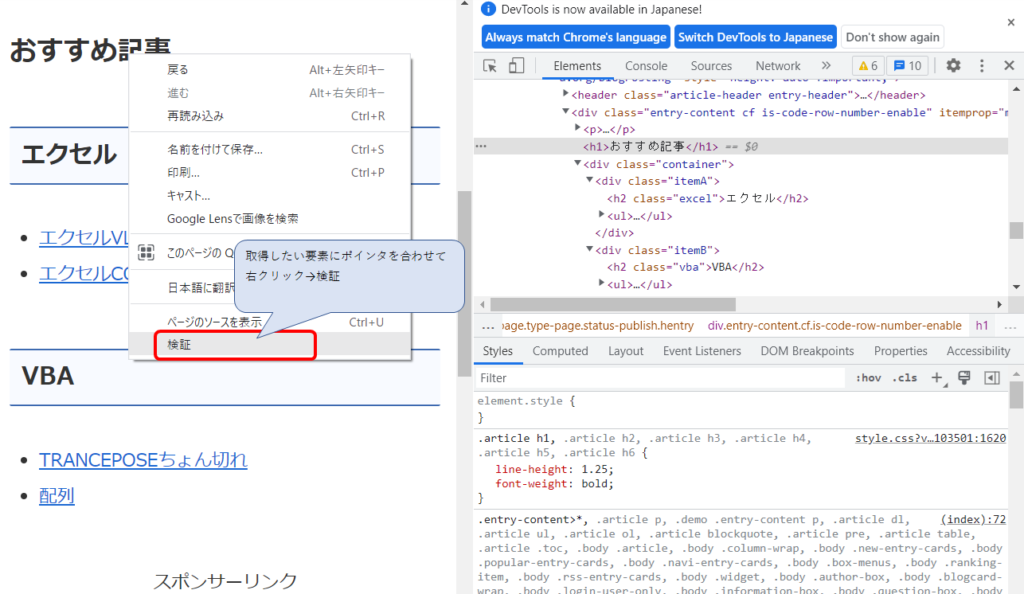
開発者用ツールを表示させるには、別の方法もあります。
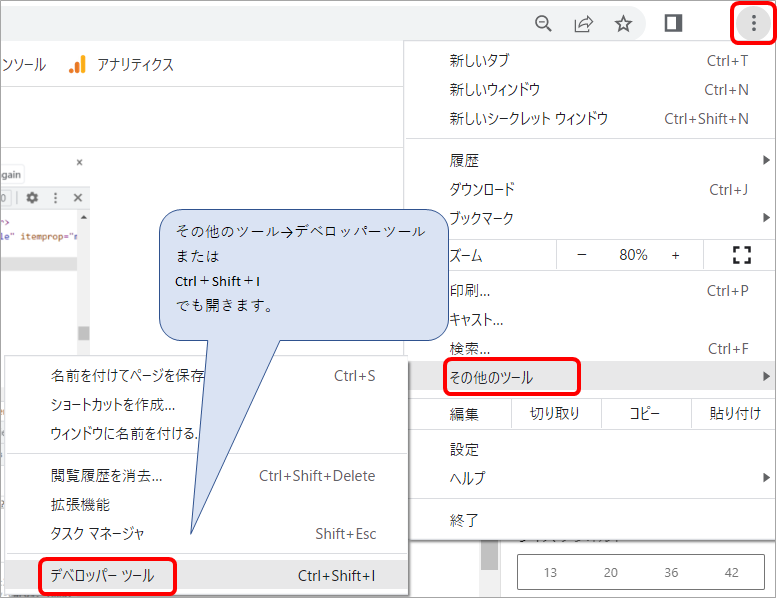
GoogleChromeの設定ボタン(右上の点3つのところ)をクリック→その他のツール→デベロッパーツール
またはCtrl+Shift+I でも開くことができます(Windowsでやってます)
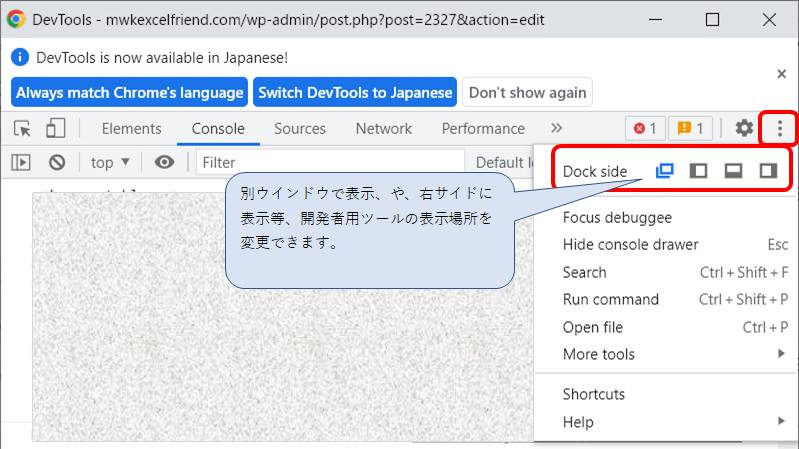
表示場所を変えるにはデベロッパーツールの設定ボタン(点3つ)をクリックして、一番上のところで切り替えできます。
3.find_elementの使用例
(1)タグで指定
find_elementを使ってみます。
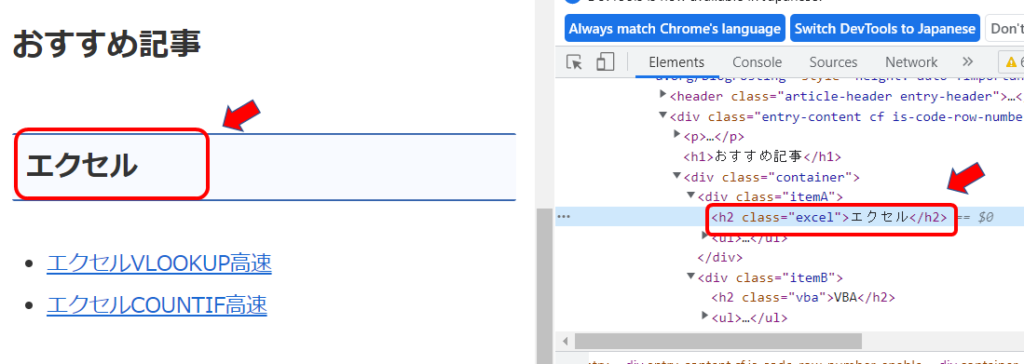
elem = driver.find_element(By.TAG_NAME, "h2")
elem.text
'エクセル'By.TAG_NAMEで「h2」タグを検索し、最初に見つかった要素がelemに入りました。
textを出力してみると「エクセル」と出力されました。
これ、ですね
find_elementsで複数の要素を取得してみます。
elems = driver.find_elements(By.TAG_NAME, "h2")
for elem in elems:
print(elem.text)同じくh2タグを検索しました。「エクセル」と「VBA」が検索されるはずです。リストで返ってくるので、elemsに格納し、forでひとつずつelemに入れてテキストを出力しました。
出力結果は以下のようになりました。
エクセル VBA Recent Posts
Recent Postsは身に覚えがないh2ですが、入ってきました。
(2)classで指定
class属性でやってみます。クラス名「excel」の要素。
elems = driver.find_elements(By.CLASS_NAME, "excel")
for elem in elems:
print(elem.tag_name,";",elem.text)出力結果。タグ名とテキストを出力しました。
h2 ; エクセル li ; エクセルVLOOKUP高速 li ; エクセルCOUNTIF高速
(3)IDで指定
By.IDをやってみました。ID=article1のhref属性を取りたかったので、IDで検索→<li>タグをelem_liに代入。その下の<a>タグを取りたいので今度はBy.TAG_NAMEで<a>タグをelem_aに代入。
属性値を取得するには get_attribute(“属性名”) でhref属性の値を取得
elem_li = driver.find_element(By.ID,"article1")
elem_a = elem_li.find_element(By.TAG_NAME,"a")
print(elem_a.get_attribute("href"))出力結果

(4)xpathで指定
同じことをxpathでやってみる。
id=article1を持つ<li>タグを検索し、その子要素の<a>タグを取得
分解すると
//li[@id=’article1′]
//はそこまでのパスを省略しているということみたい。
省略からのliタグ[]に属性を指定する。id属性なので@idと書いて属性値を指定する
で、その子供を取りたい。
/child::タグ名
と指定する。らしい。
こちらを参考とさせていただきました
https://ai-inter1.com/xpath/
elem = driver.find_element(By.XPATH,"//li[@id='article1']/child::a")
print(elem.get_attribute("href"))出力結果
(5)xpath:子孫要素
divタグクラスitemAの子孫要素を取ってみようと思います。xpathで。
子孫はdescendantです。タグはすべて取りたいので「*」を指定しました。タグ名が分からない場合はnode()とする、と書いてあったのですが、なぜかエラーになったので「*」としました。
enumerateでリストからインデックスと中身を同時に取り出ししています。
printでインデックス、タグ名、テキストを出力します。
elems = driver.find_elements(By.XPATH,"//div[@class='itemA']/descendant::*")
for index,elem in enumerate(elems):
print(index,";",elem.tag_name,";",elem.text)出力結果。
0 ; h2 ; エクセル 1 ; ul ; エクセルVLOOKUP高速 エクセルCOUNTIF高速 2 ; li ; エクセルVLOOKUP高速 3 ; a ; エクセルVLOOKUP高速 4 ; li ; エクセルCOUNTIF高速 5 ; a ; エクセルCOUNTIF高速
(6)xpath:クラス
クラス「excel」の「li」タグを取得したいと思います。xpathでやってみます。
elem_li = driver.find_elements(By.XPATH,"//li[@class='excel']")
for elem in elem_li:
print(elem.text) 出力結果。あれ、1個しか出ない。クラスexcelがついているliは「エクセルVLOOKUP高速」と「エクセルCOUNTIF高速」の二つがあるはずなのに。「エクセルVLOOKUP高速」のクラスが「excel recomend」と二つあるからでしょうか。
エクセルCOUNTIF高速
(7)xpath:contains クラス名など
を含むのcontainsを使ってみます。[]内で@classとクラス名を引数にしてcontains
elem_li = driver.find_elements(By.XPATH,"//ul/li[contains(@class,'excel')]")
for elem in elem_li:
print(elem.text) 出力結果2二つ出ました。
エクセルVLOOKUP高速 エクセルCOUNTIF高速
(8)xpath:contains テキストに〇〇を含む
テキストに〇〇を含むはtext()と指定するらしい。
elems = driver.find_elements(By.XPATH, "//a[contains(text(),'ちょん切れ')]")
for elem in elems:
print(elem.text)出力結果
TRANCEPOSEちょん切れ
seleniumムズカシイ。
xpathが〇〇の××と細かく指定できるので、使いやすいような気がします。
今日はここまで。
python webスクレイピング 超初心者の備忘録シリーズ

コメント