

正規表現については過去にやりました。
【プログラミング】正規表現って何に使うんだろう
【正規表現/VBA】VBAで正規表現を使ってみる
【Excel/VBA】VBAで正規表現~いろいろ試してみる
【Excel/VBA】VBAで正規表現~郵便番号でやってみる
パターンにマッチした文字列を取り出す、というところをやっていなかったので、今回やってみようと思います。
氏名(社員番号)という文字列から氏名と社員番号を分離して取り出したい、という場面があったのですが、よっし、正規表現でやってみよう!としたところ、あれ?おや?と四苦八苦したので、気を取り直してやってみようと。
自分の中の正規表現知りたいこと集大成、という感じでかなりネチネチやっています。どうなっているのか理屈を理解したい、という方には参考になるかもしれません。ささっと知りたい、という方はほかのサイトを見た方がいいと思います。。。
なお、正規表現のメソッドの使い方を中心にやっており、パターンの指定方法については詳しく書いていないので、別のサイトを参考にしてください。
1.正規表現の基本
正規表現については以下のサイトを毎度参考とさせていただいています。
https://userweb.mnet.ne.jp/nakama/
https://excel-ubara.com/excelvba4/EXCEL232.html
正規表現のパターンの書き方は上記サイトを参考にするとして、
VBAでの正規表現の基本を整理します。
(1)VBAで正規表現を使う
VBAで正規表現を使いたいときは、VBAの素のままでは「正規表現?は?知らね」となるので、正規表現を使えるようにする設定が必要です。
○事前バインディング
参照設定で「Microsoft VBScript Regular Expressions 5.5」を設定する。
利用するときは
Dim re As RegExp
Set re = New RegExp
と宣言とインスタンス化を行います。
reの部分はなんでもいいです。
○実行時バインディング(遅延バインディング)
参照設定をせず、使うときにCreateObjectします。
Dim re As Object
Set re = CreateObject(“VBScript.RegExp”)
正規表現のことをあれこれできることが詰まっているライブラリを参照することで、VBAでも正規表現であれこれできるようになります。
私は事前バインディングの方が好きです。
ちなみに regular expressions を日本語訳すると「正規表現」だそうです。
(2)RegExpのプロパティ
| ①Pattern | 正規表現で検索パターンを設定します |
| ②IgnoreCase | 検索の際に大文字小文字を区別するか(False=区別する/True=区別しない)。規定値はFalse(区別する)です。 |
| ③Global | 検索文字列全体を最後まで検索する(True))、最初に一致したものがあれば終わりにする(False)か。規定値はFalse(最初の一致)です。 |
(3)RegExpのメソッド
| ①Test | 検索パターンに一致するものがあればTrue、なければFalseを返します。 |
| ②Replace | 検索された文字列を指定した文字列に置き換えします。 |
| ③Execute | Testメソッドはマッチングが成功したかどうかをTrue/Falseで返します。Executeメソッドは、マッチングの結果をMatchesコレクションとして返します。MatchesコレクションはMatchオブジェクトの集合です。(引用:http://officetanaka.net/excel/vba/tips/tips38.htm) |
③については難しかったので、TANAKA先生のサイトから引用させていただきました。
以下、例です。(以降全て事前バインディングでやっています)
①Test:パターンに一致したものがあるかないかの判定
Sub testRegExp()
'検索対象文字列
Dim buf As String
buf = "abc123abc"
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc" '検索パターン abcを探す
'判定
Debug.Print "判定: " & re.test(buf)
End Sub結果(イミディエイトウインドウ出力結果)
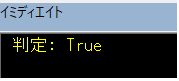
検索対象文字列中に「abc」は存在するので、判定はTrueとなりました。
testメソッドは、こうゆう文字を探したいんだけどこのパターンであってるかなあ、と事前に確かめたいときや、Replaceメソッドや、Excuteメソッドを使うときに、testでTrueだったら置換する処理をする、とか条件分岐する際に利用したりすることが多いです。
②Replace:パターンに一致したものを置換する
Sub testRegExp2()
'検索対象文字列
Dim buf As String
buf = "abc123abc"
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc" '検索パターン"
'置換
Dim buf2 As String
Debug.Print "置換前: " & buf
buf2 = re.Replace(buf, "xyz")
Debug.Print "置換後: " & buf2
End Sub結果(イミディエイトウインドウ出力結果)
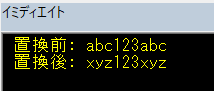
「abc」を探して「xyz」に置き換える、としています。
abc123abc が xyz123xyz になりました。
ちなみに、GlobalプロパティをFalseに変更すると、さいしょにでてきたabcだけがxyzに置換され、そのあとのabcは置換されないんですね!
re.Global = False ‘検索範囲(False:最初の一致まで検索)
③のExcuteはネチネチ深堀してやりたいので、次の項で
2.Excute:パターンに一致した文字列を取得する
Excuteがむずかしかった。Matchesコレクション?Matchオブジェクト?なんじゃ?
よくわからないので、いろいろやってみて体当たりでなんとなく理解したいと思います。
こんどはエクセルに文字列をいくつか入力してやってみます。
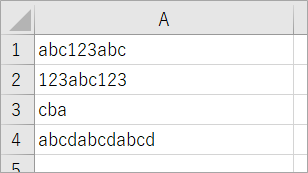
(1)MatchCollectionからヒット件数のカウント
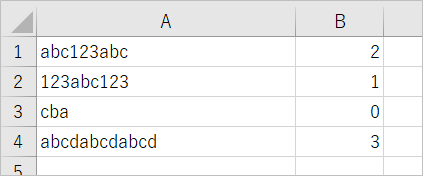
こんなコードを書いてみました。A列の文字列からabcを探し、一致した数をB列に出力します。
Sub sample3()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
i = i + 1
Loop
End Sub
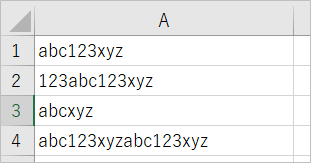
このような結果になりました。1行目はabcが2個、2行目は1個、3行目はなし、4行目は3個。想定通りですね。
(2)MatcheCollectionの中身はどうなってる?
途中で止めてローカルで変数の中身を見てみましょう。
検査対象は1行目の「abc123abc」です。
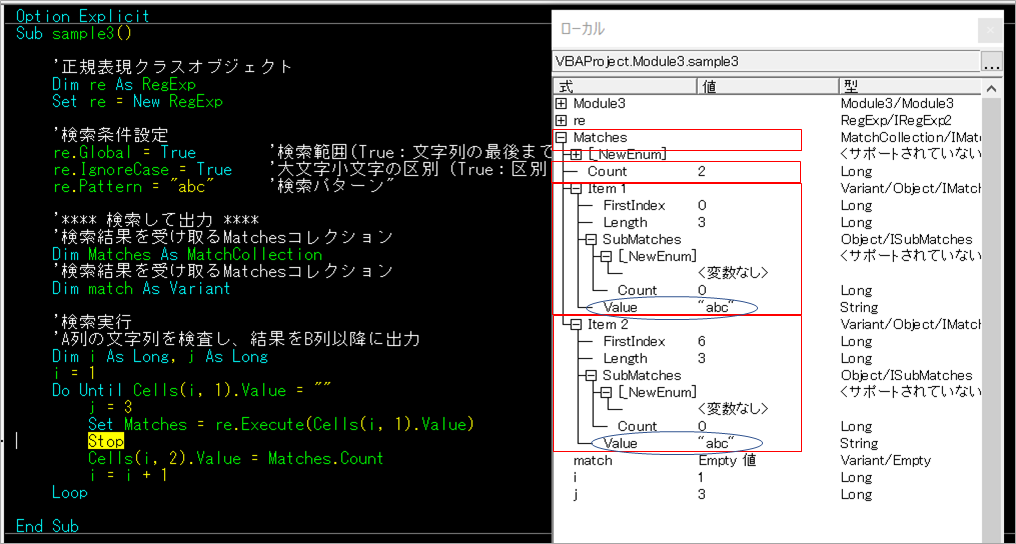
MatchesのCountが2となっていることが分かります。
Matches本体にはValueはありません。
Matchesのitemが2つあります。2つともValueが「abc」です。「abc123abc」の最初の「abc」が1つめのitemに入って、最後の「abc」が二つ目のitemに入っているのでしょう。
Itemの中に「SubMatches」というのがありますが、中身は空っぽです。「SubMatches」については後でやります。
(3)MatcheCollectionから値の取り出し~Matchオブジェクト
Value(値)を取り出したい!
Matches.item(インデックス)とすることでも、値は取り出せました。
Debug.Print Matches.Item(0)
Debug.Print Matches.Item(1)
イミディエイトウインドウ出力結果
abc
abc
matchオブジェクトとやらを使ってみましょう。MatchCollection(変数Matches)はコレクションなので、For Each で中身をひとつずつmatchに取り出していきます。
MatcdCollectionからmatchオブジェクトにいれることで、いろいろいい感じになるようです。
MatcdCollectionのItemがmatchオブジェクトに一つずつ入る感じ。
matchオブジェクトはSubMatchesやValueを持っています。
Dim match As Variantでやってますが Dim match As Match とMatchで宣言した方がよかったかも、とすべて書き終わった後で思いました。
B列にカウント数を、C列以降にmatchのValueを出力します。
Sub sample4()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
Cells(i, j).Value = match.Value
j = j + 1 '列をひとつ右へ
Next match
i = i + 1 '1行下へ
Loop
End Subこうなりました!MatchesのなかのItemをひとつずつmatchに入れて、matchのValueを出力しているということでしょう。
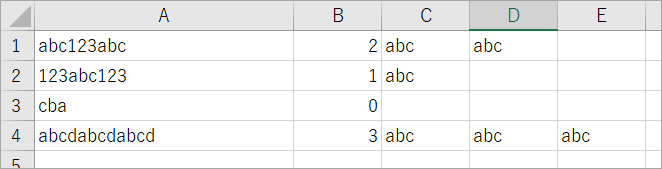
Matches(MatchCollection)からmatchに取り出した時のローカルのイメージ。変数matchのValueに「abc」が入ってます。match.Value(matchの中のValueを出しておくれ)とすることで値が出力できます。
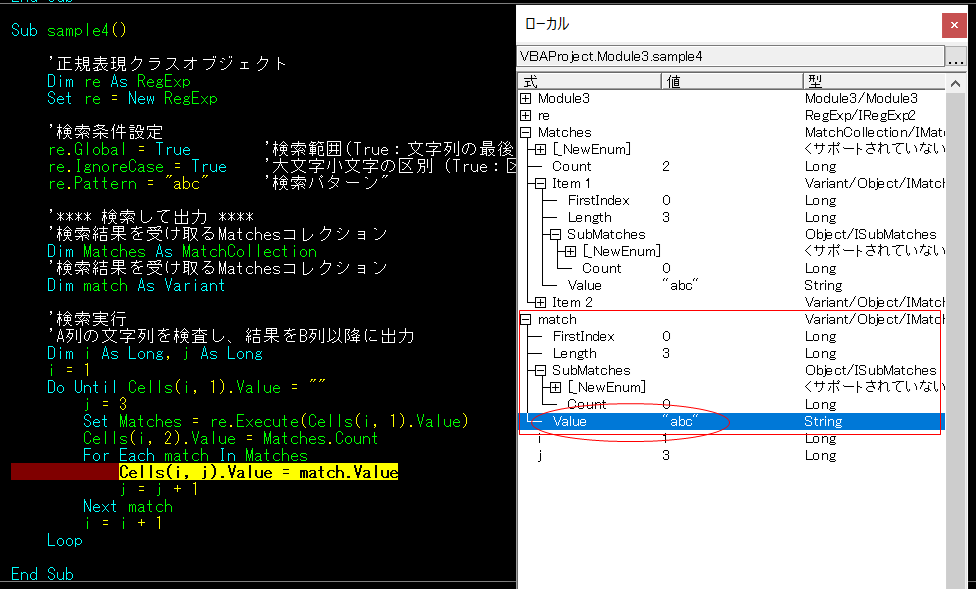
(4)パターンを[a-z]でやってみる
ここでちょっと趣向をかえて、パターンを変えてみます。
re.Pattern = “[a-z]”
[]でくくると、この中の一文字でもヒットしたらOK。
a-zとしているのでa~zまで、つまりアルファベットなら全部OK。
(IgnoreCaseをTrue、大文字小文字を区別しないにしているので大文字でもOK)
コードはこちら
Sub sample5()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "[a-z]" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
Cells(i, j).Value = match.Value
j = j + 1
Next match
i = i + 1
Loop
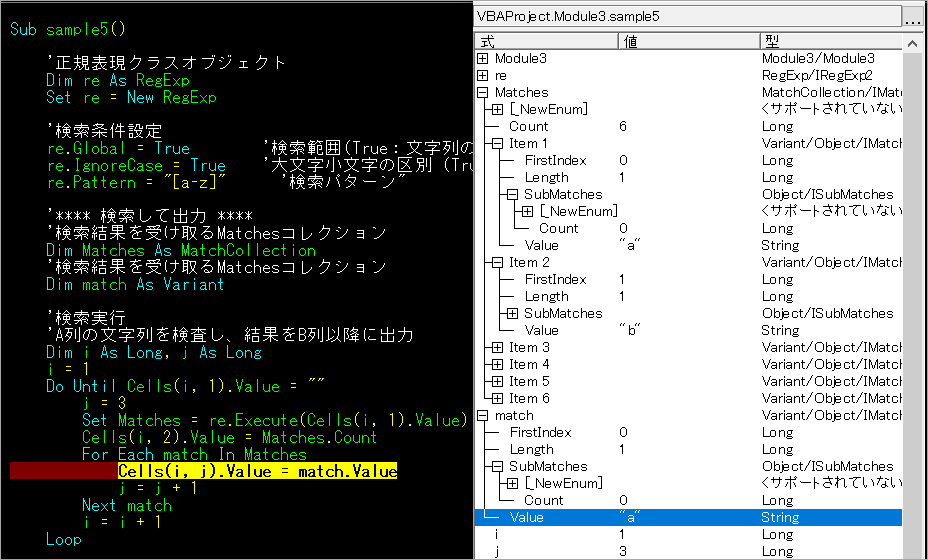
End Sub結果はこちら。3行目は大文字にしています。

1行目の途中で止めたときのローカルの様子。Matches(MatchCollection)の中にItemが6つできているのがわかりますね。
(5)()を使うとSubMatchesにはいるらしい
これまでMatches(MatchCollection)の中、matchの中もSubMatchesは空っぽでした。
しかし、見本にしたサイトのコードを見ると、SubMatchesが使われています。
どうやら()でくくってグループ化したときに()内のヒットがひとつずつSubMatchesに入るっぽいぞ、という結論に至りました。
①試してみたPart1
ちょっと表の内容を変えて、以下のコードでやってみました。
Sub sample6()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "(ab)(c)" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long, idx As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
For idx = 0 To match.SubMatches.Count - 1
Cells(i, j).Value = match.SubMatches(idx)
j = j + 1
Next idx
Next match
i = i + 1
Loop
End Sub変えたところは
①検索パターン
re.Pattern = “(ab)(c)”
同じく「abc」を探しますが、(ab)をグループ化、(c)もグループ化しています。
②Matchesコレクションのループの中に、もう一つmatchのSubMatchesのループを追加している。
Matchesコレクションの中からmatchを取り出し、そのmatchのSubMatchesを一つずつ出力する。
SubMatchesのインデックスは0から始まるので、SubMatchesの個数(SubMatches.Countで個数を取得できる)から1引いたものが最終インデックスになります。
For Each match In Matches ’Matchesからmatchを取り出す
For idx = 0 To match.SubMatches.Count – 1 ’matchの中のSubMatchesを一つずつ処理
Cells(i, j).Value = match.SubMatches(idx)
j = j + 1
Next idx
Next match
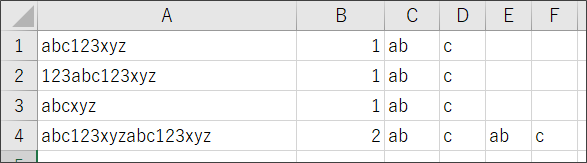
出力結果:グループ化した「ab」と「c」が分けて出力されています。
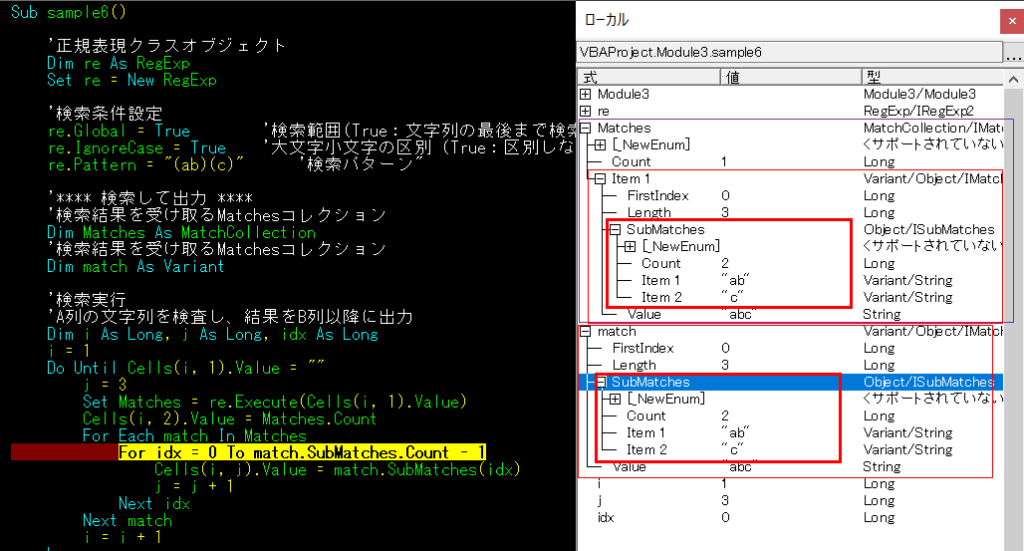
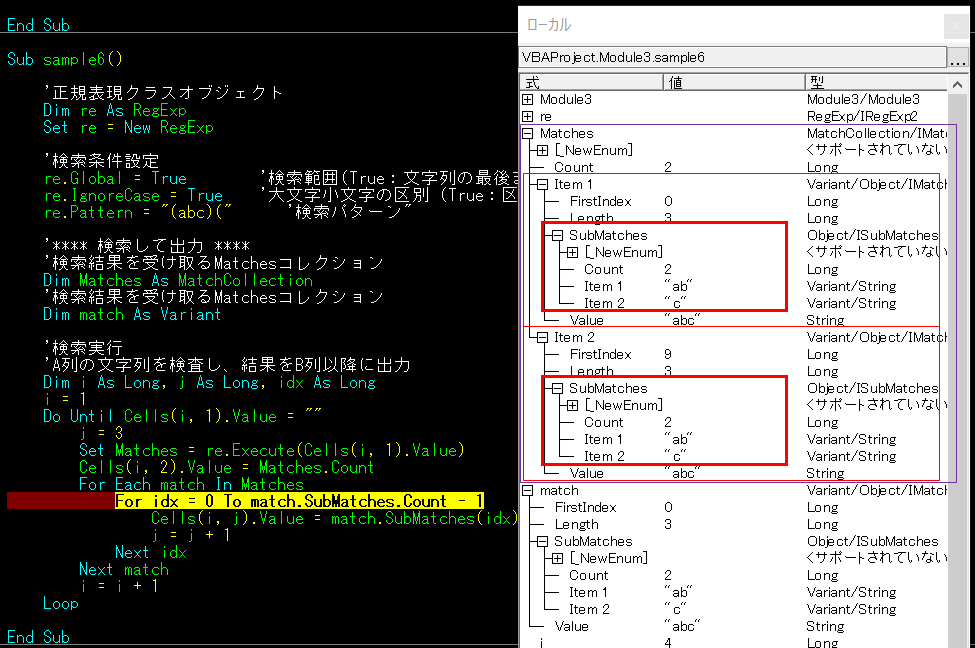
ローカルで変数の中身を見てみる。
1行目のmatchを取り出したところで止めた状態
Matchesの中のItem1のValueに検索対象の「abc」がキャッチされています。
Item1の中のSubMatchesの中のまたまたItem1に「ab」が、Itemsに「c」が入っています。
()でグループ化した通りに分割してSubMatchesに入っていますね!
MatchCollectionのItemには検索パターンの「abc」が入り、()で囲った対象はひとつずつSubMatchesのItemに入っています。
4行目で止めたときのローカル
4行目はabcが二つあるので、MatchesのItem1、Item2で「abc」をキャッチしています。
②試してみたPart2
こんどもちょっと表を変えて、abcとxyzで挟まれた3つの数字を取り出す、というのをやってみようと思います。
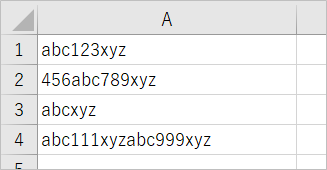
コード
Sub sample7()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc(\d{3})xyz" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long, idx As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
For idx = 0 To match.SubMatches.Count - 1
Cells(i, j).Value = match.SubMatches(idx)
j = j + 1
Next idx
Next match
i = i + 1
Loop
End Sub変えたところはパターンのところです。
re.Pattern = “abc(\d{3})xyz”
“abc\d{3}xyz” で abcで始まりxyzで終わり、その間に数字が3つ入っている文字列をさがせ!ということになります。
\dが数字を表します。{3}で直前の指定を3回繰り返しです。つまり数字3つということ。
ちなみに{1,3}で1個から3個、{5,}で5個以上などと指定することができます。
“abc(\d{3})xyz” と数字のところをカッコで囲むことにより、SubMatchesに()内が入り、出力をSubMatchesの内容としているので、検索対象文字の中から()で指定した部分の数字だけが出力されます。
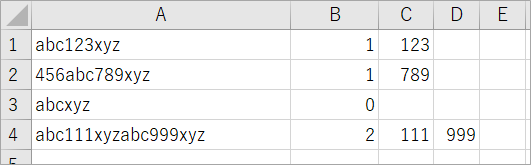
出力結果
abcとxyzに囲まれた3つの数字が出力されました。
3行目はabcとxyzの間に数字がないので、マッチせずの結果で出力もなしです。
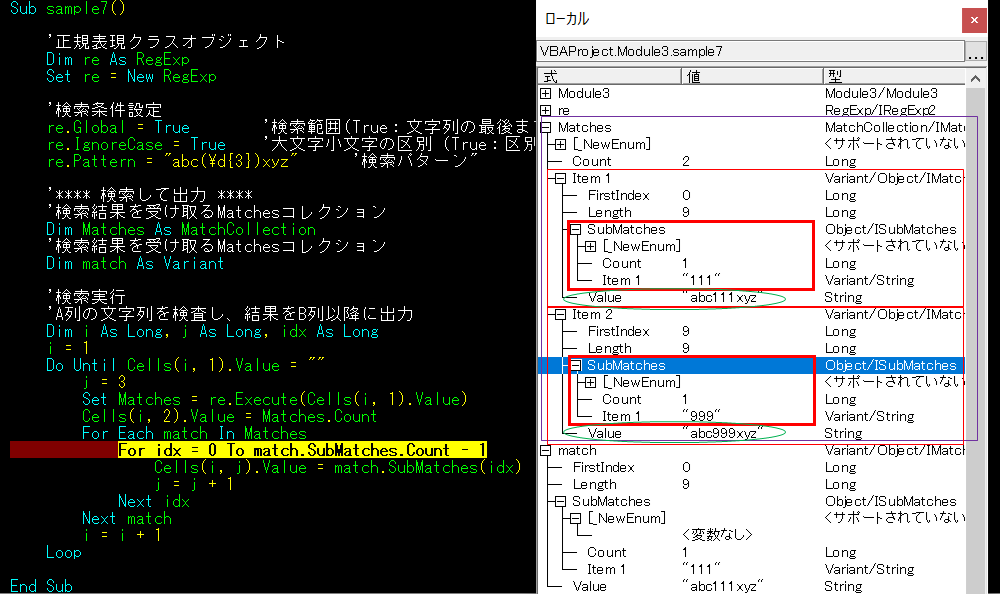
ステップ実行してローカルで変数の中身を見てみましょう。
4行目で止めたところです。
Matchesで二つの文字列をキャッチしています。Item1に「abc111xyz」とItem2に「abc999xyz」をキャッチしています。
それぞれSubMatchesには()内の数字の部分が入っています。
4.最短マッチと最長マッチ
下表でabcとxyzで挟まれた文字列を出力しよう、としたところ、あれれー?4行目は佐藤と吉田が別々に出力されてほしかったのに、最初のabcと最後のxyzで挟まれた部分がまるっと出力されてしまいました。
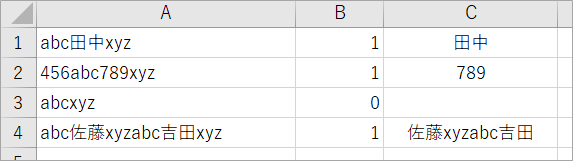
コードはこちらです。
検索パターンは
re.Pattern = “abc(.+)xyz”
と、abcで始まりxyzで終わり、その間に挟まれた一文字以上のなんもいい文字列、と指定し、abcで始まりxyzの間の部分をカッコでくくり、SubMatchesで出力しようとしています。
Sub sample8()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc(.+)xyz" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long, idx As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
For idx = 0 To match.SubMatches.Count - 1
Cells(i, j).Value = match.SubMatches(idx)
j = j + 1
Next idx
Next match
i = i + 1
Loop
End Subあれれれ?と調べたところ「最短マッチ、最長マッチ」という指定ができるそうです。
以下のサイトで勉強させていただきました。
https://step-learn.com/article/vbscript/062-regexp-long-short.html
「?」を付けることがポイント!
最短になってほしい .* や .+ の後ろに「?」を付けると、abcとxyzで挟まれた一番短い部分を検出します。
「?」を付けないと、一番長い部分を検出します。一番長い部分を検出するほうがデフォルトになっているそうです。
.* で説明すると「.*」は「何文字でもいい文字列」です。
最長マッチでは「abc佐藤xyzabc吉田xyz」からまず「abc」を探し最初に「あった!」となります。そこから終わりの目印「xyz」を探しますが、佐藤の後ろに「xyz」が「あった!でも最後まで探してみよう」となります。で、吉田のあとの「xyz」で「よし、これが最後だ。ここで決着にしよう」ということになり「.*」=「佐藤xyzabc吉田」となります。
最短マッチでは「abc佐藤xyzabc吉田xyz」からまず「abc」を探し最初に「あった!」となります。そこから終わりの目印「xyz」を探し、佐藤の後ろに「xyz」が「あった!よし、これでおしまい!」ということになり「.*」=「佐藤」となります。
なので、最短マッチにする場合は、検索パターンを以下のように書き換えます。赤字部分の?を追加しています。
re.Pattern = “abc(.+?)xyz”
すると。よかった。でたでた。
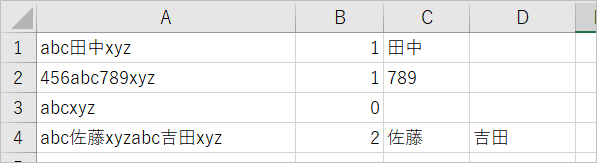
変更後のコードはこちら。変更したのはパターンのところだけです。
Sub sample8()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "abc(.+?)xyz" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long, j As Long, idx As Long
i = 1
Do Until Cells(i, 1).Value = ""
j = 3
Set Matches = re.Execute(Cells(i, 1).Value)
Cells(i, 2).Value = Matches.Count
For Each match In Matches
For idx = 0 To match.SubMatches.Count - 1
Cells(i, j).Value = match.SubMatches(idx)
j = j + 1
Next idx
Next match
i = i + 1
Loop
End Sub5.氏名+社員番号の文字列から氏名、社員番号を分離する をやってみる
A列に氏名につづいてカッコでくくられた社員番号があり、この文字列から氏名と社員番号を分離する、を正規表現を使ってやってみたいと思います。
(1)アルファベットや数字が全角の場合

やってみて、あれ?おや?なぜできぬ?とはまったポイントはかっこやアルファベット、数字が全角だったから。。。\dとやっても数字がひっかからない、なぜ?って全角だった。。。
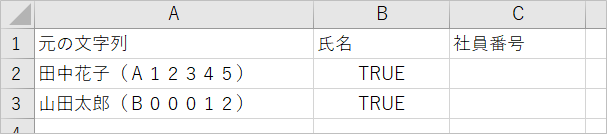
まずは、パターンを指定してみて、testでTrueになるかを確かめます。
testした結果をB列に出力します。
Sub test1()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = ".+([A-Z][0-9]{5})" '検索パターン"
Dim i As Long
For i = 2 To 3
Cells(i, 2).Value = re.test(Cells(i, 1).Value)
Next i
End Sub結果。ヒットしました。
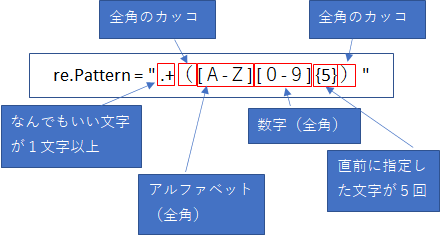
パターンを解説します。
氏名+社員番号の文字列の規則は
氏名の後にカッコでくくられて社員番号があります。
社員番号は何らかのアルファベット一文字に5桁の数字が入ります。
re.Pattern = “.+([A-Z][0-9]{5})”
. はなんでもいいひと文字、+ は直前に指定した文字が1文字以降。つまり文字が1文字以上。ここで氏名をとらえたい。
全角カッコ( これはそのまま指定します。半角の場合は指定の仕方が違います(後述します)
[A-Z] はアルファベットがなにかしら一文字。対象文字列が全角なので、AとZは全角で記述。
[0-9] は数字が何かしら一文字。後ろに{5}を付けることにより数字5文字を表します。数字も全角で記述。
さて、取り出ししていきます。
パターンにて、取り出したいところをカッコでくくります。
コードを以下のように変更します。
Sub test2()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "(.+)(([A-Z][0-9]{5}))" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long
i = 1
Do Until Cells(i, 1).Value = ""
Set Matches = re.Execute(Cells(i, 1).Value)
For Each match In Matches
Cells(i, 2).Value = match.SubMatches(0)
Cells(i, 3).Value = match.SubMatches(1)
Next match
i = i + 1
Loop
End Sub変更したところ
パターン
取り出したい部分をカッコでくくります。このカッコは半角なので注意。
カッコが入り混じっていますが、赤字のカッコが追加したものです。
re.Pattern = “(.+)(([A-Z][0-9]{5}))”
検索して出力するところ
testから書き換えました。
A列からMatchesコレクションを取得。MatchesからValueを取り出すため、Itemをmatchに入れる。SubMatchesはふたつであることが分かっているので、B列にインデックス0番目の値を、C列にインデックス1番目の値を出力する。
出力結果
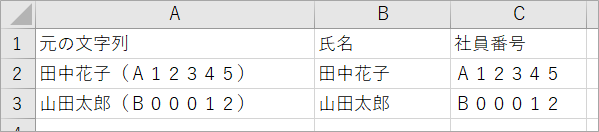
(2)アルファベットや数字が半角の場合
社員番号を半角で取り出したい、とか、全角と半角が入り混じっている可能性がある、などの場合、半角に統一したりした方がいいですよね。
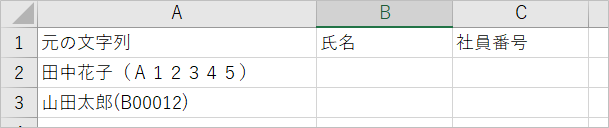
A列の文字列をStrConvで半角に変換してから検査をかけ、出力することとしました。
半角の場合はパターンの指定方法が違います。
以下のコードでは、パターンを変更しています。StrConvで文字列を半角に返還後、testで検査をかけています。結果はTrueになりました。
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = ".+\([A-Z]\d{5}\)" '検索パターン"
Debug.Print re.test(StrConv(Cells(2, 1).Value, vbNarrow))
Debug.Print re.test(StrConv(Cells(3, 1).Value, vbNarrow))パターンで変更した部分
re.Pattern = “.+\([A-Z]\d{5}\)”
色付き文字が変更した部分です。
メタ文字の前にエスケープ文字をつける
.+ は変わらず、次にカッコを指定しますが、半角のカッコの場合、そのまま指定すると「意味のある半角カッコ(グループ化のためのカッコ)」とみなされてしまうので、カッコの前に\(または/)を入力し、「意味のあるカッコじゃなくて普通に文字列のカッコだからね!」とパソコンさんに教えてあげます。終わりのカッコも同様です。「意味のあるカッコじゃなくて普通に文字列のカッコだからね!」と主張する \ のことをエスケープ文字と言ったりするそうです。
正規表現において意味のある(なにかをする力のある?)文字のことをメタ文字というそうです。
. や * や \ や ^ や + 等々
. は正規表現においてはピリオドではなく「なんでもいいひと文字」という意味を持ちます。
* は「0個以上の繰り返し」という意味を持ちます。
そんなやつらをメタ文字というそうです。
* そのものを検索したいんだけど!という場合、\* とするとパソコンさんが「ああ、*を探すのね」と理解してくれます。
アルファベットの指定
アルファベットは同じように見えますが[]内のAとZは半角です。
数字の指定
数字は半角数字で[0-9]でもよいのですが、同じ意味の\dとしました。\dは数字一文字を表します。
{5}は変更なしです。
これで取り出ししてみます。
パターンに取り出しのためのカッコを追加します。ややこしいですが、赤字が追加したカッコです。
re.Pattern = “(.+)\(([A-Z]\d{5})\)”
Sub test3()
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = "(.+)\(([A-Z]\d{5})\)" '検索パターン"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をB列以降に出力
Dim i As Long
i = 2
Do Until Cells(i, 1).Value = ""
Set Matches = re.Execute(StrConv(Cells(i, 1).Value, vbNarrow))
For Each match In Matches
Cells(i, 2).Value = match.SubMatches(0)
Cells(i, 3).Value = match.SubMatches(1)
Next match
i = i + 1
Loop
End Sub結果
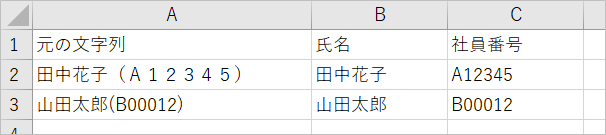
(3)VBA正規表現ではなく関数でやる
この例の場合は、関数でやった方が早くて簡単という話もあります。。。そう、ただ正規表現を使ってみたかったというだけで、悪戦苦闘し何日も費やしてしまった。。。
全角の場合の関数式
氏名取り出し:=LEFT(A2,SEARCH(“(”,A2,1)-1)
社員番号取り出し:=MID(A2,SEARCH(“(”,A2,1)+1,LEN(A2)-(SEARCH(“(”,A2,1)+1))
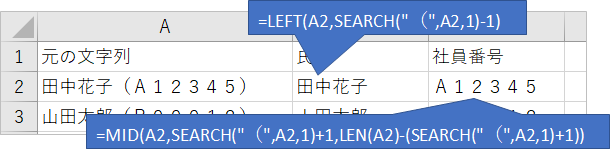
ポイントは SEARCH(“(”,A2,1) で全角(の位置を特定し、(の手前まで取り出し、とか、(の後ろから文字列数から(までの文字列数を引いた数だけ取り出し、とかしているところで。
半角全角混在の場合
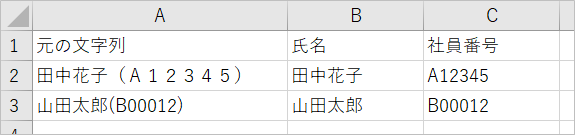
半角の場合
半角の場合の関数式
氏名取り出し:=LEFT(A2,SEARCH(“(“,A2,1)-1)
社員番号取り出し:=MID(A2,SEARCH(“(“,A2,1)+1,LEN(A2)-(SEARCH(“(“,A2,1)+1))
検索文字列のカッコを全角から半角に変更しただけです。
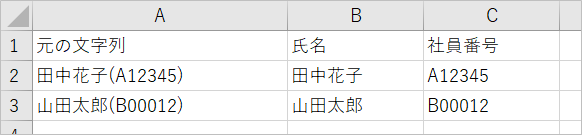
半角全角混在の場合
全角半角混在の場合の関数式
氏名取り出し:=LEFT(A2,SEARCH(“(“,ASC(A2),1)-1)
社員番号取り出し:=MID(ASC(A2),SEARCH(“(“,ASC(A2),1)+1,LEN(A2)-(SEARCH(“(“,ASC(A2),1)+1))
ポイントは、半角に統一して行っているところです。検索文字列の(を半角で指定し、検索対象文字列をASC関数で半角に変換しています。
(4)最短マッチをつかってみる
また、正規表現に戻ります。
文字列:田中花子(A12345),山田太郎(B00012),佐藤洋子(C01011) から氏名と社員番号を一つずつ取り出す、といった場合に最短マッチを使いそうだなと思ったので、やってみます。
Sub test4()
Dim buf As String
buf = "田中花子(A12345),山田太郎(B00012),佐藤洋子(C01011)"
'正規表現クラスオブジェクト
Dim re As RegExp
Set re = New RegExp
'検索条件設定
re.Global = True '検索範囲(True:文字列の最後まで検索)
re.IgnoreCase = True '大文字小文字の区別(True:区別しない)
re.Pattern = ",?(.+?)\(([A-Z]\d{5})\)"
'**** 検索して出力 ****
'検索結果を受け取るMatchesコレクション
Dim Matches As MatchCollection
'MatchesCollectionを受け取るMatchオブジェクト
Dim match As Variant
'検索実行
'A列の文字列を検査し、結果をイミディエイトウインドウに出力
Dim i As Long
Set Matches = re.Execute(buf)
For Each match In Matches
Debug.Print "氏名: " & match.SubMatches(0)
Debug.Print "社員番号: " & match.SubMatches(1)
Next match
End Subコードの解説です。
変数bufに文字列を格納して、bufを分解していきたいと思います。
buf = “田中花子(A12345),山田太郎(B00012),佐藤洋子(C01011)”
パターンを指定します。
re.Pattern = “,?(.+?)\(([A-Z]\d{5})\)”
まず、グループ化の()を外して考えてみましょう。
“,?.+?\([A-Z]\d{5}\)”
,? これは「,」があるかもしれないし、ないかもしれない、ということです。文字列の後ろの?を付けるとあってもなくてもOKということになります。最短マッチの?とは意味合いが違いますので注意。
.+? これはなんでもいい文字列(.)が一文字以上(+)。この後ろに?を付けることで最短マッチとなります。
その後ろからは解説が前の記述とかぶるので割愛します。
さらに取り出したいところをカッコでくくります。追加したカッコは緑字です。
,?(.+?)\(([A-Z]\d{5})\)”
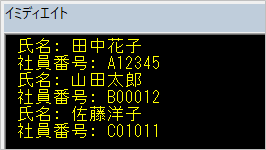
Debug.Printでイミディエイトウインドウに取り出しした氏名と社員番号を出力します。
イミディエイトウインドウの出力結果
ちなみに最短マッチの?を取るとこんな感じになります。
re.Pattern = “,?(.+)\(([A-Z]\d{5})\)”

ながくなってしまいました。これでおしまいです。
お読みいただきありがとうございました。
お役に立てば幸いですが、少なくとも私自身の備忘録としては役に立つはず!使わないとすぐ忘れちゃうんでね。。。

コメント